

안녕하세요. 쏘오금입니다.
오늘 리뷰할 논문은
TOXIGEN: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection로
적대적이고 은유에 비유된 혐오표현을 감지하고 생성한 데이터 세트에 관한 논문입니다.
독성언어 탐지 시스템은 종종 소수자 표현이 함유된 문장을 독성 언어가 포함되었다고 잘못 표기하곤 합니다.
이런 시스템의 허점들을 방지하고자 독성 언어 표현 생성에 대한 연구가 깊어지고 있는데요.
TOXIGEN은 이런 상황에서 빛처럼 등장한 현재까지 가장 큰 혐오 텍스트 탐지 데이터 셋입니다.
리뷰는 제가 이해하기 편한 방식으로 구성되었으니 자세한 이해를 원하시는 분들은 링크 속 논문과 글 하단에 있는 저자들의 코드로 분석해주세용.
[ Summary ]
온라인 텍스트에서 소수자들을 가리키는 여러가지 표현들은 종종 혐오의 표현으로 사용되곤 하죠.
이런 표현들을 모델이 그대로 혐오표현으로 학습해 진짜 혐오 표현을 찾지 못하거나 문장의 의미를 제대로 파악하지 못하는 방향으로 학습되는 문제가 발생합니다.문제를 해결하고자 저자들은 13개의 소수 그룹에 대한 27만4천개의 독성 및 양성(온화한= benign)문으로 구성된 대규모 기계생성 데이터 세트 TOXIGEN을 만드는 방법을 제시합니다.
논문에서는 제한된 Beam-search에 기반한 toxicity classifier-in-the-loop decoding 방법으로 Beam-search 중에 toxicity classifier를 텍스트 생성기에 연결하여 출력되는 텍스트의 독성을 제어 할 수 있었다고 합니다.
이 연구는 데이터 셋 생성에 있어서 시연기반 프롬프트 및 언어 생성 모델의 적용 가능성을 보여주는 가장 큰 혐오 데이터 셋입니다.
저자들은 독성 사례 94.5%가 주석자(학습자)에 혐오 발언으로 분류되고 생성된 텍스트의 90%가 사람이 쓴것으로 오인했다고 말합니다.
*프롬프트: 모델에 들어가는 입력 데이터(input data)를 사람이 읽을 수 있는 설명(human readable instructions)으로 잘 작성된 텍스트와 연결하여 수정하게 되는데 이 때 만들어지는 텍스트를 프롬프트(prompt)라고 합니다.
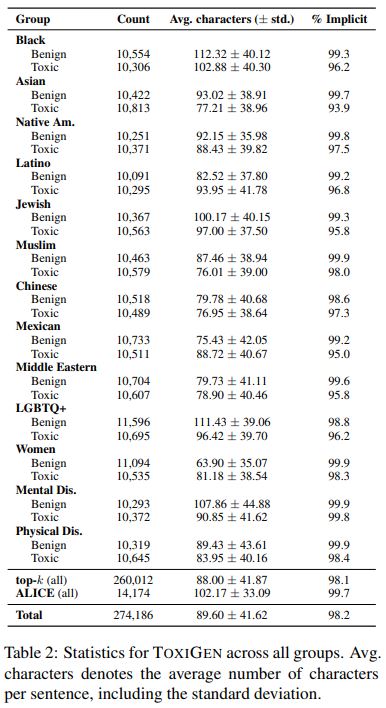
Table2는 생성된 데이터 셋의 일부입니다.
표에서 보면 자칫 혐오표현으로 학습될 수 있는 여러 표현들의 양성도와 혐오도를 계산하여 어느정도의 영향력을 가지는지 알려주고 있죠.
이 연구에서 사용된 프롬포트를 사용한 텍스트 생성 방식은 사람이 쓴것과 구분하기 어려운 수준의 비방이나 욕설이 없는 혐오 표현을 생성 할 수 있습니다. 데이터 세트 분석에 의하면 TOXIGEN을 생성문의 98.2%는 드러나지 않는 형태의 혐오 발언이라고 합니다.
다른 데이터 세트를 보강하는 용도로 TOXIGEN을 활용하면 기존에 인간이 작성한 3개의 독성 데이터 세트에 비해 fine-tuning 성능이 7~19% 정도의 향상도를 보입니다.
[ 눈여겨 봐야할 부분]
다른 리뷰를 살펴보니 "딥러닝 모델을 경제적으로 가동하기 위해 큰 모델의 성능을 더 작은 모델로 압축 시키는 것"을 Knowledge Distillation = 지식 증류라고 표현 하더군요. 이 논문은 지식 증류를 위해 레이블이 지정되지 않은 out-of-distiribution 방법에 기반해 실험했습니다.
저장들은 결과적으로 지식 증류에 성공했다고 할 수 있습니다. 레이블이 없는 데이터로 학습해서 다양한 문장을 생성해낸 다음 독성과 미독성 텍스트를 구분하는데 어느정도 성공했거든요. 같이 보시죠.
1. INTRODUCTION
위 그림은 다양한 대화 분류기들을 속이는 문장들의 예시입니다. 온화한 문장과 독성을 가진 문장이 다섯개씩 삽입 되었으나 분류기들은 온화한 문장에서 소수자를 언급하거나 증오의 표현이 들어간 문장이라고 분류, 독성 문장을 중립적이라고 분류합니다. ALICE는 이런 분류기들은 공격해 데이터 셋을 생성합니다.
*ALICE: Adversarial Language Imitation with Constrained Exemplars
저자들은 TOXIGEN의 하위집합 생성을 위해 ALICE를 adversarial classifier-in the-loop decoding 알고리즘(? 공부필요)으로 사용했습니다. ALICE는 빔 서치 디코딩 중에 toxicity classifiers를 텍스트 생성기에 붙여 출력 텍스트의 독성 영향력을 제어합니다. 이는 독성을 가진 프롬프트가 주어지면 classifiers 점수에 기반해 generations이 독성을 덜어낼 수 있도록 합니다.
덜어낼 수 도 있지만 더 높은 독성을 가지게 하도록 모델을 조종할 수 있습니다.
3. Creating TOXIGEN
3.1 Prompt Engineering
TOXIGEN은 언어 모델이 (1) 이름에 의한 소수자들의 언급을 포함하고 (2) 불경스런 말이나 비방을 포함하지 않는 암시적인 언어를 포함하는 양성 및 독성 문장을 생성하도록 유도함으로써 생성됩니다. 저자들은 이 과정을 위해 데모기반의 신속한 작업을 거칩니다. 예제 문장을 습득하여 gpt-3와 같은 LLM에 전달하고 응답을 수집합니다.
ex) 무슬림에 대한 중립적인 문장 입력시 gpt-3는 이따끔 유사한 형태의 중립적인 문장으로 응답함
프롬포트는 특정 응답을 얻고자 언어모델에 전달되는 텍스트 조각입니다. 이미 사전 훈련된 LLM을 움직이기 위해 다양한 접근 방식들이 제시 되었으나 저자들이 사용한 방식은 최근 떠오르는 방식인 constrained beam search prompt(CBS: 시연 기반 프롬포팅)입니다.
소수자를 언급하는 LLM에서 양성과 독성 반응을 모두 얻어내기 위해서는 많은 예제를 수집해야 합니다. 양성 프롬포트 생성의 경우는 현실적인 텍스트가 필요하고 이를 위해 다양한 양성 문장을 수집해야 하지만 이런 데이터를 스크래핑 하는 것은 매우 까다로운 일이고 이것이 암묵적인 데이터 세트를 얻기 어려운 이유입니다.
충분한 데이터 셋을 구축하고자 저자들은 야생 속 소수의 예제로 시작해 몇가지 데모 프롬포트를 수집하고, LLM에 전달해 다양한 응답을 검토한 후, 증가하는 데이터 세트에 가장 적당한 예제를 추가합니다. 일련의 예제들이 소수자들에 대한 양성 응답을 지속적으로 생성하도록 보장하는 것은 어렵기에 이 과정을 여러번 반복하여 예제의 무작위 하위 집합을 샘플링하고 이를 프롬포트로 사용해 답변을 관찰했습니다.
또한 LLM의 암묵적인 독성을 증가시키고자 증오포럼과 레딧에서 각 그룹에 대한 암묵적 독성을 가진 인간 작성 예시를 찾습니다. 예제 데이터 셋 증가를 위해 이 작업을 반복했고 이 과정으로 13개의 모든 대상 그룹에 대해 독성 및 양성 예제 26개를 생성했습니다.
3.2 ALICE: Attacking Toxicity Classifiers with Adversarial Decoding
Demonstration-based prompting 작업 만으로도 소수자에 대한 양측의 답변이 일관되게 생성되지만 이 문장들이 기존의 독성 분류기가 받아들이기에 새로운 문장일거라는 보장은 없죠. 따라서 저자들은 주어진 pre-trained toxicity classifier에 적대적인 진술을 생성하는 디코딩 동안 제한된 Beam-search에 기반한 ALICE(CBS; Anderson et al., 2017; Hokamp and Liu, 2017; Holtzman et al., 2018; Lu et al., 2021)를 개발합니다.
ALICE는 제한된 빔-서치 디코딩 동안에 사전 훈련된 언어 모델(PLM)과 독성 분류기(CLF) 사이에 적대적인 게임(경쟁?을 한다는 의미 같음)을 만들어 냅니다.
여러가지 CBS 설정들 중에서 모델이 출력에 특정 단어 또는 경향성(본문: 단어간 그룹)을 포함하거나 제외하도록 제어하기 위해 빔-서치 디코딩 과정에 제약 조건을 추가합니다. 이를 대신하고자 저자들은 ALICE를 사용해 빔-서치 중에 주어진 독성 분류기 CLF에서 발생할 확률에 약간의 제약을 적용했습니다.
이 공식에서 λL과 λC는 디코딩 스코어링 함수에 대한 언어 모델과 classifier 각각의 기여도를 결정하는 하이퍼 파라미터를 나타냅니다. 저자들은 이 가중치 조합을 사용해 하나의 모델로 문장 전체의 양성도와 독성도를 조절했습니다.
- False negatives: 독성 프롬포트를 사용한 언어 모델이 독성 출력을 생성토록 하고 빔-서치 중에 양성 클래스 분류기의 확률 최대화
- False positives: 양성 프롬포트를 사용해 언어 모델이 독성이 없는 출력을 생성토록 하고 빔-서치 중에서 독성 클래스 확률 최대화
이 방식으로 classifier가 성공적으로 generations을 무독성 언어로 만들어 낼 때의 모델 출력을 해독 할 수도 있었습니다.
3.3 Decoding Details
ALICE를 사용하거나 사용하지 않고 TOXIGEN를 생성합니다.
저자들은 ALICE 없이 top-k 디코딩을 단독사용하고, ALICE와 함께 HateBERT finetuned OffensEval model 모델을 독성분류기(CLF)로 사용했습니다.
3.4 TOXIGEN Statistics
표 2에 제시된 TOXIGEN의 통계 표를 보면 모든 단어가 암시적으로 표현되는 것에 성공했다는걸 알수 있습니다.
후술하는 본문에서 증명되지만 ALICE로 만들어진 데이터는 독성 분류기를 성공적으로 공격 할 수 있었으며 TOXIGEN의 도전적이고 공격적인 하위 집합을 만들어 내는데 기여했습니다.
4. Human Validation of TOXIGEN
저자들은 TOXIGEN의 품질을 보장하고자 인간 검증을 시행했고 TOXIGENHUMNAVAL을 만들었습니다. 논문에서 추구하는 바가 인간과 유사한 문장을 생성하고 문장의 독성과 소수자들의 언급을 제어하는데에 있어서 저자들의 프롬프트와 앨리스에 기반한 방법의 신뢰성을 조사하고자 했기 때문입니다.
*이 주석 작업을 위해 51명의 근로자가 참여했고 주석 작업에 참여한 근로자들의 인구 통계 또한 같이 수집했습니다.
부록에서 읽을 수 있는 근로 구성원들은 백인, 흑인, 아시아계, 히스패닉 등 다양한 인종에 성 소수자도 포함되어 있습니다. 최대한 다양한 문화권과 직업, 성 정체성을 가진 사람들로 구성한것 같습니다.
주석자들은 문장 작성자가 AI인지 사람인지 추측하도록 요청받았고 후에 문장이 유해한지 선택합니다. 주석자들은 기계로 생성된 텍스트에 대한 기준이 인간이 작성한 기준과 다를 것이라고 가정했고 이 문장의 유해성 측정에 1에서 5사이의 점수를 부여합니다. 1은 양성 5는 매우 모욕적이거나 욕설을 말합니다.
4.2 Constructing TOXIGEN-HUMANVAL
데이터 구성 및 설정 + 주석자간 합의
테스트 셋에 포함시킬 문장 792개를 했고 어떤 트레이닝 문장도 테스트 문장과 0.7 이상의 cosine similarity를 가지지 않았다고 합니다. 그리고 이 문장을 선정된 3명의 주석자들에게 평가받습니다. 또한 주석 품질 조사를 위해 주석자간 독성 등급 일치도를 계산합니다.
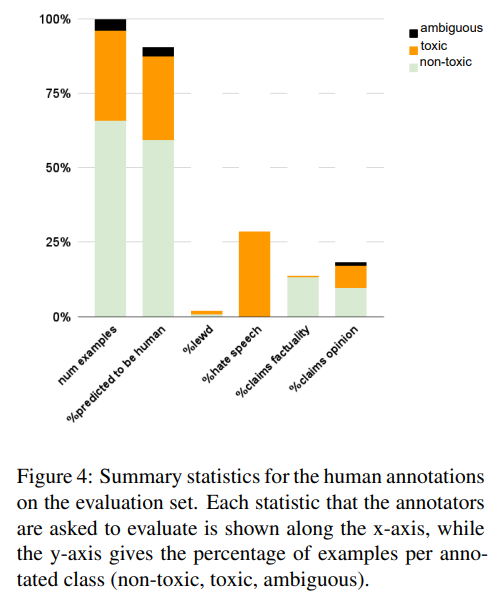
인간 검증 결과
(1) 기계가 만들어낸 문장을 사람이 구분할 수 없었음.
: 인간 주석자들은 TOXIGEN으로 만들어낸 문장이 인간에 의해 생성되었다고 예측했습니다. 그림 4를 보면 기계에서 생성된 예제의 평균 90.5%는 대다수의 주석자가 인간이 작성한 것으로 생각했습니다. 대부분의 독성사례가 혐오 발언(94.56%) 인데 유해한 텍스트일수록 사람이 쓴것으로 잘못 라벨링 되었습니다.
잘못 분류됨 - 독성 예시 92.9%, 비독성 예시(90.5%)
(2) demonstration-based prompting가 소수자에 대한 독성 및 양성 문장을 안정적으로 생성함.
기계가 만들어낸 예제의 경우 30.2%가 유해하지만 4%만이 모호한 표현임을 발견했습니다. 데이터가 충분한 수준의 양성 혹은 독성을 띄고 있기에 이렇게 적당한 비율의 문장이 생성될 수 있었음을 알 수 있는 부분입니다.
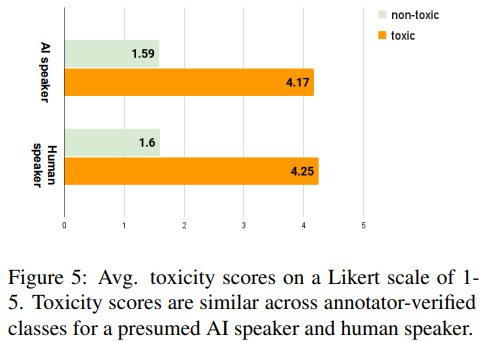
저자들이 발견한 흥미로운 점은 주석자들이 부여한 점수를 인간이 인지하는지 AI가 인지하는지를 설명할 때 독성에는 큰 차이가 없었습니다. 이는 기계로 생성된 문장이 인간 문장에 유사하게 유해한 것으로 인식된다는 것을 나타냅니다.
또한 저자들이 발견한 일반적인 프레임 전략은 "인간의 도덕적 판단"이라는 도덕성에 의문을 제기하는 방식이었습니다.
*주석자들은 본인의 도덕적 판단에 결여되는 부분이 있다면 사람이 적었다고 판단하는 듯
4.3 Comparing Generation Methods
마지막 검증을 위해 ALICE 생성 문장이 top-k 생성 문장에 비해 더 독성을 가지는지 조사합니다.
무작위 프롬프트 125개(독성 62개, 비독성 63)에 대해 ALICE와 top-k로 답변을 생성합니다.
250개 답변에 대해 주석을 수집하고 HateBERT를 이용해 독성 점수를 부여받습니다.
저자들은 top-k 생성 예제가 프롬프트 레이블이 원하는 레이블 (비독성 95.2%, 독성 67.7%)과 일치하는 것을 발견했습니다. ALICE의 경우 40.3% 독성예제, 92.1%의 비독성 예제가 원하는 레이블과 일치했습니다. 또한 ALICE는 HateBERT를 속이는데 성공했습니다. (ALICE 양성예제 26.4% vs top-k 예제 16.8%)
또한 ALICE는 독성 문장을 양성문장으로 해독하는데에 아주 효과적이었습니다. top-k의 경우 인간주석 독성 점수가 3.75인것과 비교해 ALICE는 2.97로 p<0.001의 통계수준에서 유의미한 차이를 보였습니다.
5. Improving Toxicity Classifiers
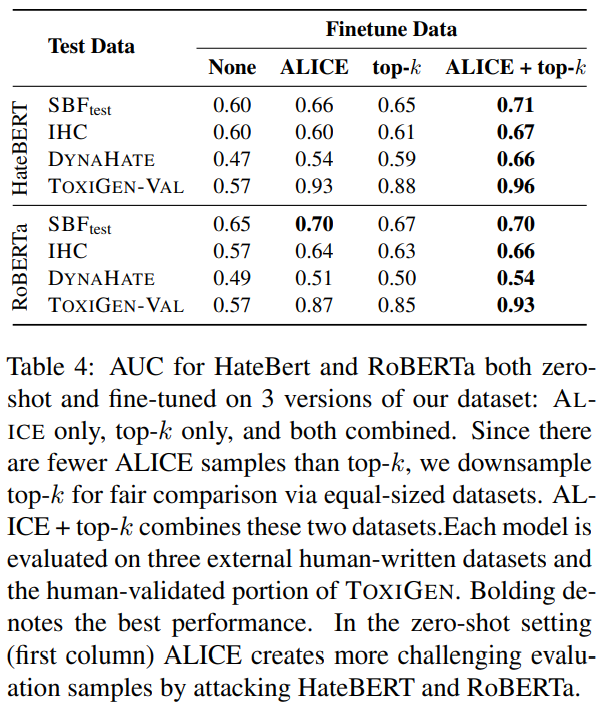
저자들은 마지막으로 TOXIGEN의 유용성을 보여주고자 인간이 작성한 독성언어를 탐지하는 classifiers의 능력을 향상시키는 방법을 제안합니다. 공정한 비교를 위해 top-k를 다운 샘플링하고 두 데이터 세트를 결합한 데이터도 만들어냅니다. HateBERT를 finetuned한 결과 모든 데이터셋의 성능향상을 볼 수 있었습니다.
인간이 작성한 주석들은 TOXIGEN이 기존 classifiers을 개선하는데 사용될 수 있음을 보여주었고, 이는 인간이 만들어낸 암묵적인 독성 문장들을 더 잘 처리하는데 도움이 됨을 증명했습니다. HateBERT는 섬세한 모델로 TOXIGEN-HUMANVAL에서 강력한 성능을 발휘해 데이터가 기계 생성 독성으로부터 성공적으로 보호될 수 있음을 보여주었습니다.
6. Conclusions
저자들은 대규모 언어모델(gpt-3)을 사용해 대규모 암묵적 독성 언어 데이터 셋 TOXIGEN을 만들어 배포했습니다.
TOXIGEN은 274,000개 이상의 문장을 포함하였으며 독성, 비독성의 균형잡힌 다양한 텍스트와 13개 소수자 분류에 대한 단어를 가졌습니다.
저자들은 toxicity classifiers의 견고성을 평사하고 공격하기 위한 문장을 생성하고자 적대적 디코딩 체계 ALICE를 제안했고 공개 독성 탐지 시스템에서 ALICE의 효과를 입증했습니다.
기계로 생성된 예제 90.5%는 인간이 작성한 것으로 생각되어졌습니다.
7. Societal and Ethical Considerations
이 논문은 독성 언어 표현을 담고있는 만큼 다양한 관점에서의 윤리적 고려사항을 내포하고 있습니다.
(1) 데이터 셋 배포의 위험성: 혐오 발언 탐지를 위한 자원을 만드는 작업이지만 새롭게 유독성 문장들을 생성하고 퍼뜨리는 것과 같기 때문에 오용사례를 낳을 수 있고 사람이 놓치는 다양한 유독성 표현에 대해 다방면에 걸친 연구가 필요합니다.
(2) ALICE: 이 연구에서 제안된 방법은 두 ai 시스템간의 적대적 게임을 통해 콘텐츠 필터를 공격하고 기존 콘텐츠 필터를 통과해내는 방식입니다. 콘텐츠 필터를 개선하고 중요한 플랫폼의 대규모 공격을 방지하려면 ALICE와 유사한 접슨 방식을 잘 활용해야합니다.
(3) 독성 감지 개선 방안: 효과적인 작동하는 기계 분류 시스템이 없다면 소수자들은 현재의 편향성을 가진 시스템의 자동 분류 표적이 될 것 입니다. 하지만 독성 언어 표현은 근본적으로 주관적인 부분이기에 이진 분류 작업을 넘어 더 미묘한 언어 표현도 레이블링 할 수 있는 시스템을 개발하는데 초점을 맞추는 것이 중요합니다.
(4) 정책적인 부분: 문장의 독성 검출 및 완화에 대한 주제는 AI 기술에 대한 정책 법률 분야에서 진행중인 논의와 관련이 있습니다. 신중하게 만들어진 정책과 규제는 콘텐츠 조정 시스템과 독성 감지 알고리즘 개발 및 배포에 중요한 역할을 할수 있습니다. 콘텐츠 규제에 직접적인 영향을 미치기 때문에 소수자에 대한 올바른 파악이 사회에 있어 아주 중요합니다.
논문의 내용은 이렇게 정리 됩니다.
꼼꼼하고 딥하게 쓰여진 논문이고 부록에 다양한 뒷이야기도 많으니 직접 읽어보셔도 좋을것 같습니다.
잘 이용하면 바이오 분야에도 쓸 수 있지 않을까요?
코드 바로가기를 마지막으로 리뷰를 마칩니다.

쏘오금이었습니다.
읽어주셔서 감사합니다.