
안녕하세요.
오늘 리뷰해볼 논문은
"Analysis of sentiment in tweets addressed to a single domain-specific Twitter account: Comparison of model performance and explainability of predictions"

제가 이해한 바로는 Feature Extraction에 관한 다양한 방법을 직접 실험해보고 가장 좋은 성능을 얻어 내는 방법을 탐구해나가는 논문 같았습니다.
서로 다른 기계학습 모델의 성능을 평가방법을 제안하고 비교하면서 마지막장에서는 시각화 하는 방법도 제안합니다.
왜 같았습니다....냐면... 뭔가 이해가 잘 안되었거든요.
글의 짜임새나 내용의 흐름은 좋은데 그래서...뭘 한건가 싶은 느낌.
하지만 추후 다른 분들의 연구를 위해서 힘든일을 대신 해준 느낌도 받았습니다.
시작해 봅시다.
INTRODUCTION
저자들이 정한 연구의 목표는 다음과 같습니다.
(1) 최신 Transformer model을 포함해 선택된 NLP 모델을 논문에서 다루고 있는 Sentiment@USNavy(이하 navy)을 이용하여 비교함.
(2) 이 모델의 품질이 SemEval-2017(이하 sem) 대회에 참가한 팀이 달성한 결과와 어떻게 비교되는지 보여주고자 함.
(3) 모델의 예측을 더 잘 이해하기 위해 최신 XAI 기술들을 Twitter 감정 분석에 어떻게 사용할지 보여줌.
정확한 분석을 위해 다른 논문들과 방법론들에서 제시하는 다음과 같은 방법을 도입하였습니다.
(1) 트위터 데이터에 대한 감정의 세분화된 분류를 위한 navy 데이터 세트 (Fiok, 2020)
(2) navy 데이터 세트 및 sem 작업 4 데이터 set를 최신 트랜스포머 모델을 포함해 선택한 LM(언어 모델)의 품질 시연
(3) 최신 XAI 기법을 사용하여 트위터에서 감정 분류를 위해 선택된 LM과 품질 - 설명 가능성에 대한 트레이드 오프를 제시
(4) 선택된 최근 Transformer 모델을 기반으로 비지도 ML 방법을 통해 추출된 주제 관련 정보가 감정에 미치는 영향을 조사
sem DATA와 비교하기 위해 sem 데이터를 만드는 방법과 동일한 matrics를 사용했고 이렇게 만들어진 데이터 세트로 분석합니다.
2.1 데이터 세트
navy 데이터 세트 준비 과정은 다음과 같습니다.
[1] 데이터 정제
(1) 공식@USNavy 계정의 2011.1 ~ 2019.12 까지의 트윗 데이터 130,688개
(2) 이미지, 주소, 리트윗에 대한 게시글을 "_IMAGE", "_RETWEET", "_URL 토크나이징, 26,523개 제거
(3) 공식계정의 자체 게시글 199개 제거
(4) 일부 외국어를 포함한 게시글을 미 표준 ASCII 기호에 따라 임의의 연산식을 구성, 계산후 ASCII 점수 부여.
점수가 0.2 보다 큰 경우 알아들을 수 없는 문자가 많다고 판단하여 834개 삭제
(5) 비영어권 트윗 1905개 삭제
(6) 이미지 토큰을 가진 4자 미만의 트윗 2,405개 삭제
98,822개 중 random 하게 5000개를 추출해 train 데이터로 6000개, test 데이터로 20,632개의 데이터를 사용.
[2] 분석 준비 - 레이블링
비교군으로 선택된 sem data의 감정 레이블은 0, 1, 2, 3, 4로 '부정' 부터 '매우매우 긍정' 까지 존재.
이와 같은 구조로 레이블링 작업
(1) RANDOM하게 선택된 트윗 5000개에 3명의 연구원이 독립된 상태에서 수동으로 레이블 작성
(2) krippendorf alpha 주석일치 측정기로 계산해보니 3명의 연구자가 작성한 주석의 일치도가 0.592의 낮은 결과값을 보임.
(3) 주석을 통일하고자 다음과 같은 방법 사용
- 모든 주석자에게 같은 점수를 받은 경우 : 주석 점수를 유지한다. (count: 1934개)
- 다수의 주석자에게 같은 점수를 받은 경우: 다수의 점수를 유지한다. (count: 2223개)
- 모두에게 다른 점수를 받은 경우: 추가 주석자의 점수를 부여한다. (count: 843개)
[3] SemEval-2017 데이터와 비교
완성한 navy 데이터와 가장 유사한 작업 데이터는 SemEval-2017의 sub-task 4C와 4E로 이중 4C는 MMAE를 평가의 절대 척도로 사용. 부가 평가 지표로 MAE 채택.

- (h, TE): 문서에 대한 예측, 본래 레이블의 감정군
- Xi: Tej의 문장 집합,
- Cj: (xi ∈ Tej)의 감정 class
- yi: 올바르거나 원래 레이블링된 감정군
- h(xi)는 예측된 감정 레이블
- “distance difference” |h(xi) − yi |: 실제 class 레이블까지 예측되는 거리
2.4. Models for feature extraction
세가지 유형의 feature extraction 모델 사용.
1) 설명가능한 특징 추출기
- TF, Linguistic inquiry and word count (LIWC), Sentiment analysis and social cognition engine (SEANCE)
2) task 별 데이터에 대한 training을 받지 않은 DEEP Learning 특징 추출기( 토큰 임베딩 평균은 트윗 레벨 임베딩)
- RoBERTa, FastText, Universal sentence encoder (USE)
3) #1. task 별 데이터에 대한 training을 받은 DL( trained LSTM에 의해 트윗 레벨 임베딩으로 변환된 토큰 임베딩)
- Bidirectional LSTM with FastText, Bidirectional LSTM with RoBERTa
#2. task 별 데이터를 fine-tuned 하는 DL(built-in-transformer LM classification(CLS) output에서 제공하는 트윗 레벨 임베딩)
- fine-tuned RoBERTa, BERT, XLNet, BART Large case, fine-tuned XLM-R, XLM MLM en 2048
표 1에 선택된 특징 추출기가 나와있음.
2.5. ML models and computing machine

FE 모델의 output은 표 2에 제시된 매개변수와 함께 XGBoost의 Gradient Boosting ML Classifier에 입력.
2.6. Cross-validation
상대적으로 적은 데이터 샘플로 인한 편향을 최소화하기 위해 가능한 경우에 한해 실험을 교차 검증한다.
교차 검증 절차를 두가지로 정의한다.
1) FE가 교육되는 단계동안의 교차 검증
2) ML 분류 중에 하는 교차 검증
@USNavy data set, SemEval-2017 data set k-fold cross-validation 이행
+2.7 그룹 |||의 경우
트윗 레벨의 벡터 표현을 생성하고자 bidirectional LSTM 을 사용한 3그룹 FE는 후술 작업에서 [CLS] 출력을 사용하기 위해 FINE TUNED시 다른 매개변수 집합을 활용했다. 이전 연구에 기반해 훈련 매개변수를 최적화하지 않는다,
2.8. Statistical analysis of results
테스트를 완료한 모델 중에 일부가 비슷한 결과를 도출하여 이를 평가하기 위해 bootstrap 통계 분석 방법을 적용.
MMAE metric을 이용해 값 분포를 bootstrap한다. 정확한 값 도출을 위해 10,000 리샘플링하고 계산했으며 다른 모델과의 차이에 통계적 유의성을 계산했다.
도출된 MMAE 값을 p-value값의 유의 수준 접근 방식으로 평가한다.
p > 0.1: 모델간에 통계적으로 유의한 차이가 없다.
* 0.1 > p > 0.01: 약간의 차이를 가진다.
** 0.01 > p > 0.001: 차이를 가진다.
*** 0.001 > p : 매우 큰 차이를 가진다.
2.9. Explaining model decisions
ML 모델의 예측의 근거에 대한 사용자 이해를 제공하고자 XAI 기반의 SHAP 사용.
이중 SHAP tree explainer를 사용하여 선택된 여러가지 GB 모델 variants에 대한 시각화를 생성.
transformer LM을 위해 Bertviz 시각화 방법 사용. 이는 분석된 샘플 트윗에서 LM의 "Attention" 메커니즘에 의해 식별되는 토큰간 연결을 시각화해 표현함.
2.10. The influence of topic-related information on sentiment predictions
결과로 도출되는 트윗 topic에 대해 지식으로서 활용하고자 이미 개발된 두가지 유형의 topic 접근 방식 소개
1) LDA(Latent Dirichlet Allocation)와 같은 비지도 ML 기법으로 추출한 정보를 활용하는 접근법.
- 트윗에 내포된 sentiment 의 일부분을 논의하는데 그치지 않고 sentiment 의 대상도 분석 할 수 있음.
2) topic 정보를 ML sentiment 예측 과정의 특징으로 활용하여 모델의 성능을 향상시키는 접근법.
- 이 접근법은 LDA에서 추출한 기능을 다양한 단어 임베딩과 함께 사용한 선행 연구에서 등장함.
두가지 접근법에 이르렀을 때 연구자들은 예측 성능이 증가했다고 보고, 그러나 모두 DL Transformer 구조 외부의 가정 예측 모델에서 일어난 성능 증가로 보였다고 함.
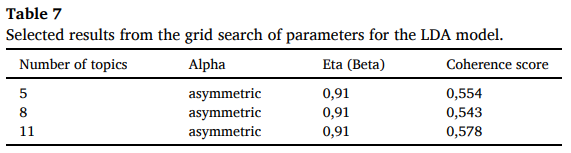
이때 LDA는 사용자가 직접 선택한 3가지 매개 변수( 문서 분할 주제의 수, 알파 & 에타(베타))에 따라 결과가 다양해진다.
저자들은 5 ~ 20개의 topic 그룹을 포함해 450개의 매개변수 조합을 따르는 gird search를 수행해 저자들 판단하의 적절한 LDA 모델을 선택했다.
LDA 모델의 품질과 결과 주제는 키워드 간의 의미론적 유사성의 척도인 일관성 점수로 측정된다.
그러나 점수 산출시에 다양한 갯수의 주제 그룹을 채택하는 모델에서 각 그룹의 일관성 점수가 매우 유사할 시 설득력 없는 결과를 산출할 수도 있다.
3. Results and discussion
NAVY data set 에서 선택된 FE 모델의 성능이 모든 지표에서 그룹간에 크게 다른걸 확인 할 수 있음.
가장 낮은 성능을 가지는 것은 EFE 모델, 데이터에 대한 훈련이 없는 모델은 약간의 성능 개선을 보였다.
훈련된 FE 모델은 최상의 결과를 얻었으며 이는 SEM data set의 훈련 결과와도 일치한다.
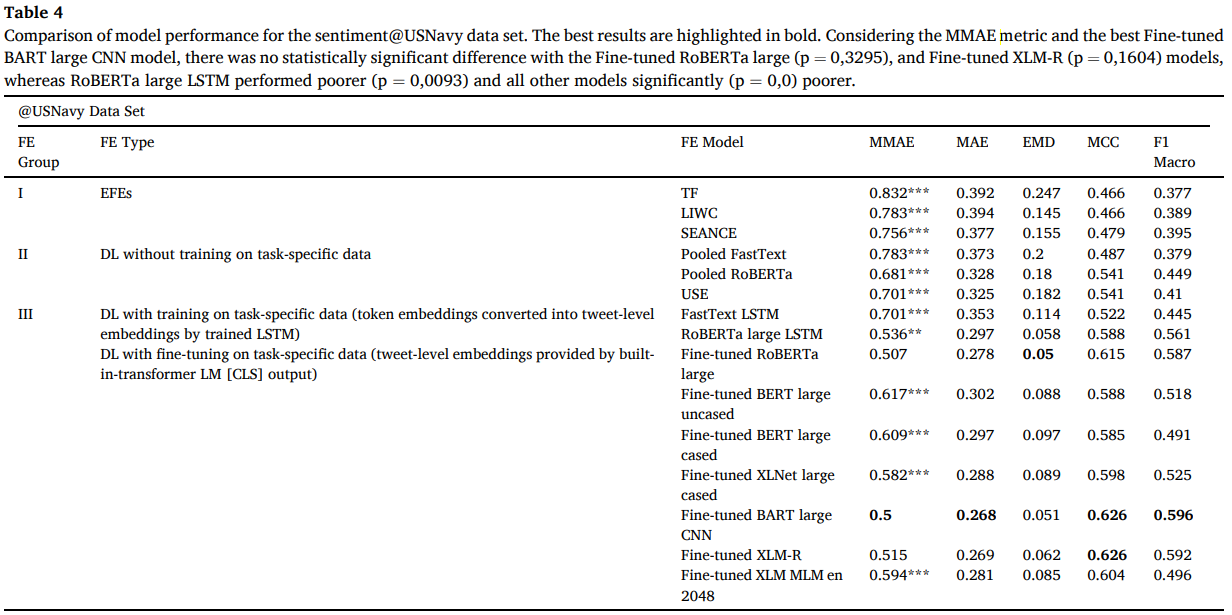
SENTIMENT@USNavy에 대한 모델 성능 비교.굵은게 잘된 것.
MMAE 메트릭과 최고의 Fine-tuned BART 대형 CNN 모델을 고려할 때, Fine-tuned RoBERTa 대형(p = 0,3295) 및 Fine-tuned XLM-R(p = 0,1604) 모델과 통계적으로 유의한 차이가 없었던 반면, RoBERTa 대형 LSTM은 성능이 저하(p = 0,0093) 및 기타 모든 모델에서 현저하게 저하되었습니다.
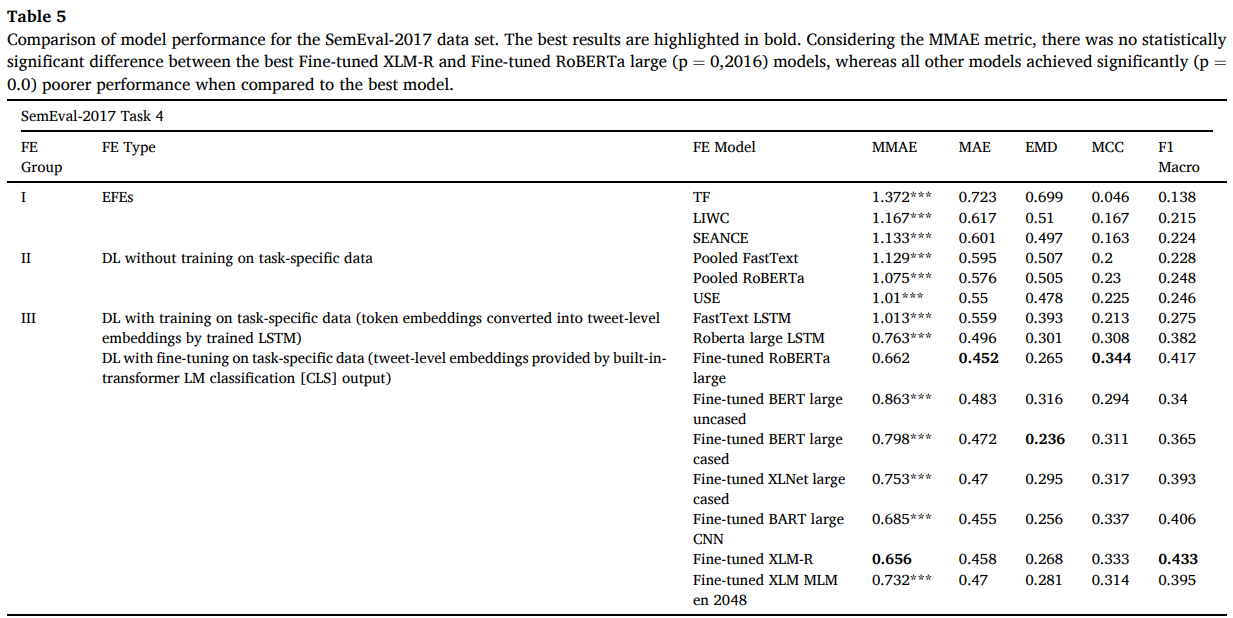
SemEval-2017 데이터 세트에 대한 모델 성능 비교. 굵은게 잘된 것.
MMAE 측정 기준을 고려할 때, 최고의 미세 조정 XLM-R과 미세 조정 RoBERTa 대형(p = 0,2016) 모델 사이에 통계적으로 유의한 차이가 없는 반면, 다른 모든 모델은 최상의 모델과 비교했을 때 상당히 낮은 성능(p = 0.0)을 달성했습니다.
전체적인 분석 결과
1) 두 데이터 세트 모두에서 트윗 수준의 언어 벡터 표현을 생성하고자 fine-tuned transformer 모델의 special classification [CLS] output을 사용한 FE 모델에서 가장 좋은 결과를 얻음.
2) 두 데이터 세트 모두에서 single-transformer 모델이 모든 실험 과정에 대해 실패적인 결과를 도출.
3) DL FE를 out-of-the-box solutions으로 사용, 즉 Task의 사전 교육 없이 사용했을 때 USE와 RoBERTa는 비슷한 결과를 도. USE는 약간 더 높은 성능을 보임.
4) EFE 모델을 비교시 SEANCE가 두 데이터 세트 모두에서 LIWC 및 TF 보다 약간 우수한 것으로 보임.
그러나 TF는 매개변수 조정 절차를 적용할 시 성능이 변경되고 두 방법 다 완전한 학습은 불가능 함.
5) NAVY data set의 감성분석 작업은 SEM data set를 이용한 과거의 작업보다 쉽다. 더 나은 성과를 달성하기 때문인데 이는 아날로그 sem data에는 인스턴스가 테스트 셋에 포함되어 모델이 overfiting되기 때문이다.
3.2. Side experiment
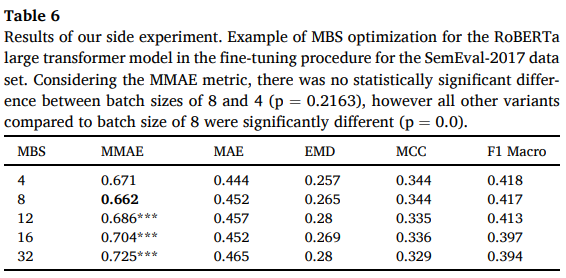
그룹 III의 FE 훈련 모델( task별 데이터에 대한 훈련이 필요한 훈련 가능한 Deep Learning 특징 추출기 ) 의 편향 가능성.
그룹 III은 훈련 매개변수의 모델별 최적화가 수행되지 않았으므로 채택된 변수 집합이 한 모델을 다른 모델보다 선호하는 결과를 도출할 수 있음.
매개변수 선택 과정에서 DL 모델 성능이 저하되거나 개선되는 정도를 설명하고자 부가 실험 수행.
RoBERTa Large LM을 사용하는 FE에 대해 선택된 MBS(mini-batch size) 값이 성능에 미치는 영향 평가
- 이들 중 5중 교차 검증 부가 실험의 결과가 표 6
: sem 데이터 set에 대한 fine-tuned 과정에서 RoBERTa Large Transformer 모델에 대한 MBS 최적화에 대한 예시.
*MMAE 공식을 고려하면 배치 크기 8과 4 사이에 통계적으로 유의미한 차이 (기각역 0.1에서 p= 0.2163)가 없었지만, 배치크기 8과 비교한 다른 모든 variants들은 유의미한 차이를 보였다 (p = 0.0)
이 차이에 대한 고찰은 실제 sem 대회 순위표에서 6위와 7위를 달성하는 차이를 보였다.
저자들은 여기서 매개변수 최적화는 METRIC에 따라 달라져야 한다는 가설을 세울 수 있었다.
3.3. XAI for sentiment analysis in Twitter
저자들은 감성분석에 사용되는 설명가능한 AI의 구성을 위해 SHAP 기반의 FE 시각화의 예시와 식별 가능한 token 간의 어텐션 메커니즘 연결과정을 시각화하여 보여준다.
제공된 시각화 자료는 모두 단일 모델에 대해 생성하였으며 교차 검증되지 않은 데이터이다. 이 시각화 자료는 ML 모델의 최종 결정에 기여한 5개의 가장 중요한 기능의 평균 범위를 관찰 가능하다.
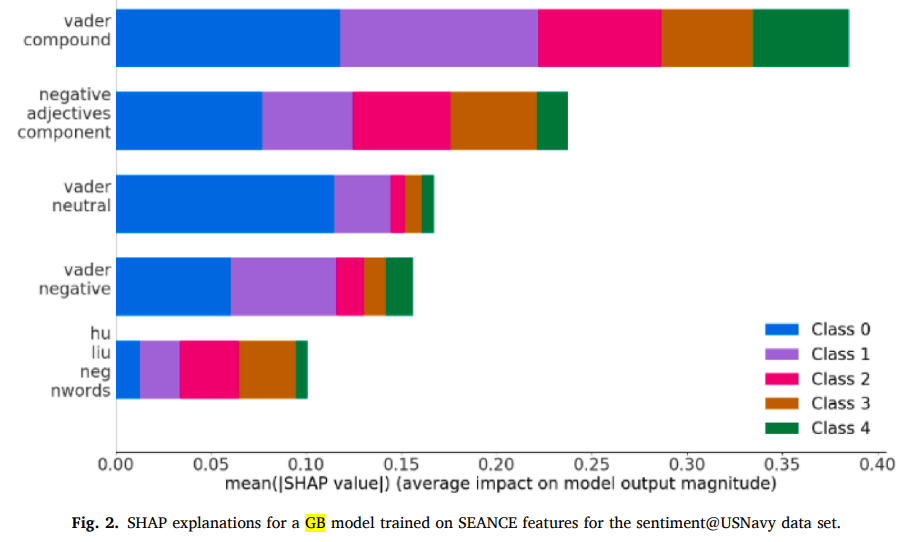
그림 2는 NAVY 데이터 세트에 대한 SEANCE 기능에 대해 훈련된 GB 모델의 SHAP 설명 시각화 자료이다.
SAENCE에서 추출한 모든 어휘기반 기능중에서 VADER 기능이 매우 중요한 역할을 한다는 결론을 내릴 수 있었다.
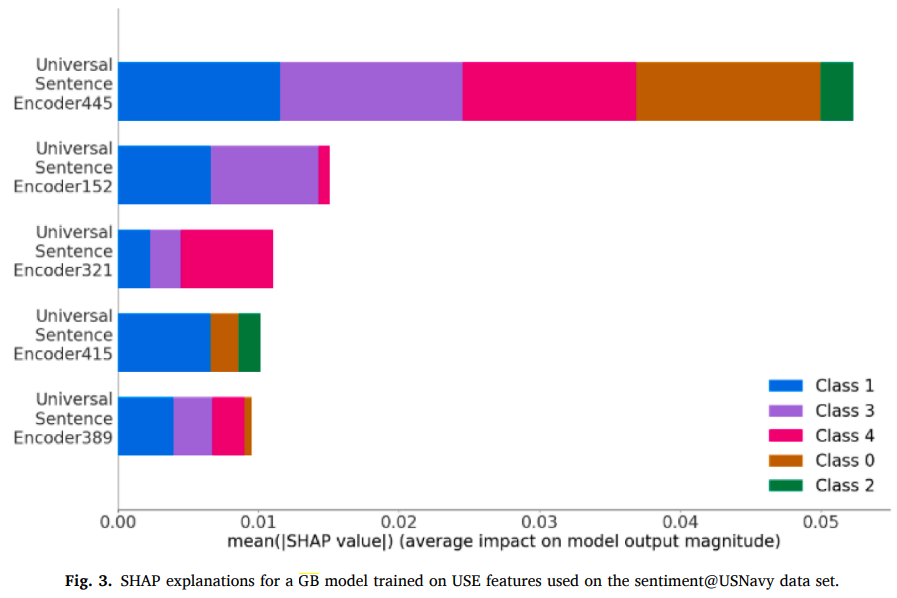
그림 3 NAVY 데이터 세트에 대한 USE 기능에 대해 훈련된 GB 모델의 SHAP 설명 시각화 자료이다.
USE 모델의 Feature는 인간의 해석을 허용하지 않기 때문에 SHAP 설명을 기반으로 보여지는 Feature의 영향들이 다른 Feature가 미치는 영향보다 더 중요한걸 알 수 있었다.
저자들의 연구에 사용된 다른 DL FE도 인간은 각 주어진 Feature와 다른 Feature들이 무엇인지 이해할 수 없었다.
이는 높은 품질의 DL FE의 심각한 한계이다. 즉, ML 모델 예측의 근거에 대한 설명이 불가능하다는 말이다.

문장의 토큰 컨텍스트에 따라 변경되지 않는 simple static word embeddings을 수행하는 LM에 기반한 LSTM이 생성한 텍스트 표현의 경우, 모델 예측에 대한 이론적 근거의 인스턴스 수준 시각화를 생성할 수 있다. 또한 순환 신경망을 사용하는 text 수준의 LM에 대해 이러한 시각화가 가능함을 보여주었으나 이러한 예측 모델들은 최신 성능을 따라오지 못한다. 대중적이지도 못한 시각화 방법들은 우리가 쉽게 사용가능한 시각화 소프트웨어 패키지가 없음을 보여주었다.
선행 연구자들은 이러한 LM에서 사용되는 Attention mechanism의 focus를 시각화 하는 방법을 제안했습니다.
이 방법으로 transformer model의 각 layer와 attention head를 확인할 수 있으며 각의 조합 생성을 가시적으로 보여준다.
이 시각화 방법은 그림 4에서 보여주는 것처럼 트윗 레벨의 통찰력을 보여줄 수 있으며 이를 통해 토큰 간의 연결이 평가에 사용된 모델에 의해 올바르게 식별되는지 확인 할 수 있다.
트윗의 올바른 분류를 위해 transformer model이 출력하는 트윗 레벨 embeding에 영향을 미친다는 것을 나타내는 [CLS] 토큰과 가시적으로 연결되는 토큰을 고려 할 때, 모델이 식별하는 토큰은 “Thank,” “wonderful,” “Dad,” “e” (beginning of “eulogy,"이다. 그중에서도 “sharing” 과 “memories” 기억은 강하게 연결되어 있으며 “your”과 “Dad.”는 같은 phenomenon이 발생하지 않는다.
이 고찰에서 알 수 있는 것은 Attention mechanism이 토큰간의 연결을 올바르게 구분하였다는 것,
보다 중요한 것은 [CLS] 토큰에 영향을 미치는 토큰이 진정한 핵심 토큰인 반면 "for" 또는 "the"는 [CLS]와 연결되지 않았다는 것이다.
3.4. Second side experiment – the influence of topic-related information
비지도 학습으로 훈련된 ML을 통해 추출된 Topic 정보가 선택한 최신 transformer 모델을 기반으로한 sentiment prediction에 미치는 영향을 조사하기 위해 LDA 모델 작업을 포함하는 두번째 side 실험 수행
1) 채택된 LDA model 매개변수의 Grid search로 시작해 표 7에 제시된 것처럼 유사한 coherence score를 가진 여러 매개변수 조합을 도출,
2) 5개 topic과 11개 topic을 가정한 모델은 5개 주제를 채택하면 sentiment class의 수를 모방하고 11개 주제를 채택하면 이 varients가 가장 높은 coherence score를 산출하기에 LDA로 각 데이터 인스턴스에 대해 유추된 주제를 사용하기로 결정함.
실험의 다음 단계는 각 데이터 인스턴스에 대해 LDA 모델에서 발견한 topic이 ML 감정 분류 파이프라인에 기능으로 공급.
저자들이 선택한 transformer model과 품질 비교를 가능케 하고자 세 가지 기능 조합을 꾸림.
- 1. 오직 LDA topic feature
- 2. fine-tuned RoBERTa Large model에서 추출한 feature
- 3. fine-tuned RoBERTa Large model에서 추출한 feature만 포함된 LDA topic
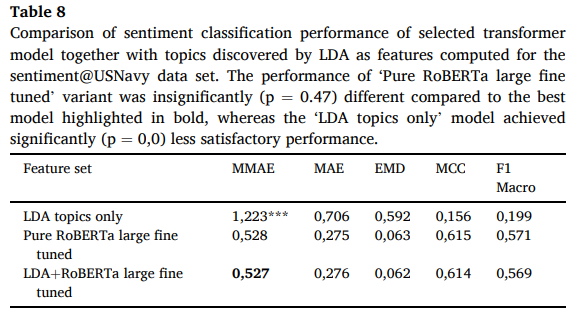
이 분류 작업의 성능은 표 8과 같다.
선정된 transfomer 모델의 sentiment 분류 성능과 sentiment에 대해 계산된 feature로 LDA가 도출한 TOPIC 비교
'Pure RobERT a large fine tuned' variant 모델 성능은 굵은 글씨로 강조된 제일 좋은 모델과 비교해 0.47의 p값, 유의하게 다른 반면, 'LDA topics only' 모델은 성능(p = 0.0)에 도달에 실패.
결론은 다음과 같다.
1) 추출된 LDA topic을 ML Classifier에 의해 단독으로 분석할 때 예측 품질이 낮다.
2) 선택한 RoBERTa model에서만 제공되는 기능의 사용과 LDA 항목을 비교하면 어떤 모델이 더 나은 성능을 발휘하는지 결정 불가능하다.
- 이는 다음과 같은 가설을 세울 수 있다.
"transformer model에 의한 텍스트 데이터에서 파생된 독립 변수와 함께 LDA topic을 feature로 사용하는 것이 항상 예측 성능을 향상 시키는 것은 아니다."
저자들은 여기서 실험 해석을 다음과 같은 이유로 중단했다.
- 1. 작은 data set 하나만 사용했다.
- 2. 임의로 선택된 Transformer model 만 사용했다.
- 3. LDA model의 매개 변수의 선택은 연구자에 따라 다르고 문제를 동반한다.
- 4. LDA model output을 feature로 사용할 수 있는 방법은 여러가지가 있으며, 이 연구에서는 가장 가능성있는 topic만 feature로 사용했다.
4. Study limitations
이 연구의 한가지 한계점은 이전에 언급한 FE 매개변수 최적화의 부족으로 인한 편향 가능성이다.
TF와 같은 사전 훈련 가능한 FE 방법의 경우 매개변수 최적화 부족이 성능에 영향을 미칠 수 있는 정도는 이전의 연구들에서 증명 되었고 저자들의 Transformer 적용 실험에서도 입증되었다.
5. Conclusions
1. 이 연구는 하나의 트위터 계정으로 전달되는 트윗으로 구성된 트위터 감정분석 작업을 위해 새로운 데이터 세트를 도입했다.
2. 선택된 LM로 실험을 수행해 사용된 데이터 세트의 유용성을 입증했다.
3. 성능을 입증하기 위해 SemEval-2017 데이터 세트에 최신 Transformer 모델을 포함해 다양한 모델을 배포했다.
4. 정교한 최적화 과정이나, 추가 training data 또는 text 없이도 Transformer 모델이 성능 경쟁에서 높은 순위를 차지하는 것을 발견했다.
5. 비지도 ML 으로 추출한 feature topic을 사용하여 transformer 모델로 얻은 예측 성능을 높일 수 있는지에 대한 질문을 다루었고 이 주제는 더 연구되어야한다.
6. 트위터 감정 분석에서 XAI 도구 사용이 가능하지만 인간이 이해할 수 있는 LM 모델에 한해 사용이 제한됨을 실험으로 보여주었다.
감사합니다.
이해가 안되는게 있으시다구요?
하ㅏㅏ하 저도요.
감사합니다.