
#INFOBERT
https://github.com/AI-secure/InfoBERT
GitHub - AI-secure/InfoBERT: [ICLR 2021] "InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspe
[ICLR 2021] "InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective" by Boxin Wang, Shuohang Wang, Yu Cheng, Zhe Gan, Ruoxi Jia, Bo Li, Jingjing Liu -...
github.com
논문에서 자주 언급되는 약어들
"QA" : Question Answering
"NLI": Natural Language Inference
"MI" : mutual information
Contribution
- 언어 모델의 Adversarial Robustness를 개선하기 위해 정보 이론적 관점(information theoretic perspective)에서 InfoBERT를 제안한다.
- 이론적 지원을 통해 다양한 NLP작업에서 표준 훈련과 적대적 훈련에 적응 할 수 있는 상호 정보 MI(Matual information)를 기반으로 하는 두개의 Regularizers가 포함되어 있다.
- InfoBERT는 benign dataset에서 정확도를 잃지 않고 NLI와 QA의 여러 Adversarial dataset에서 SOTA를 달성했다.
*standard training: 원래 훈련 데이터만으로 훈련
*Adversarial training: 원래 훈련 데이터에 적대적 사례를 포함한 것으로 훈련
4. Experiments
4.1 Experimental SETUP
실험에 사용한 Adversarial dataset와 Adversarial attacks
(i) Adversarial NLI (ANLI) (Nie et al., 2020)

ANLI 데이터 세트는 BERTlarge의 정확도를 0%로 가장 쉽게 줄여주는 강력한 adversarial dataset임
(ii) Adversarial SQuAD (Jia & Liang, 2017)
이 실험에서는 adversarial training 데이터가 제공되지 않기 때문에 benign SQuAD training data (Rajpurkar et al., 2016)에서만 RoBERTaLarge를 fine-tuned하고 benign과 adversarial set 모두에서 모델을 테스트함.
(iii) TextFooler (Jin et al., 2020)
문자의 특정 단어를 동의어로 대체하여 자연어 처리 시스템이 다른 텍스트로 오해하도록 속이는 소프트웨어
논문에서 다루는 적대적 예제의 전체적인 도안은 다음과 같다.
저자들이 주목하는 위협모델(threat model)은 지배적인 단어 수준 공격이다.
이런 공격 모델은 다른 공격보다 더 높은 공격 성공률을 달성하면서 독자의 눈에 잘 띄지 않는다.
그런데 지배적인 단어 수준 공격(dominant word-level attack)이 뭘까?
첨부자료나 언급이 없어서 찾게되면 추가하겠음...
저자들이 말하기를 텍스트를 입력 받는 공간의 이산적 특성 때문에 단어나 문장 같은 토큰 수준에서는 적대적인 단어 변형(본문: 왜곡[distortion])을 측정하기 어렵다고 한다.
대신, 대부분의 word-level adversarial attacksdms에서 의미를 임베딩 하는 공간의 제한된 크기를 이용해 단어 perturbation을 제한하기 때문에 이 임베딩 공간에서 제한된 수준에서 변형된 적대적 텍스트 예제를 정의한다.
ϵ : 제한된 텍스트 적대적 예제
(1) 먼저 문장 x가 주어진다. 이때 문장 x는 [x1,x2,,,,xn]으로 구성되어지며 xi은 i번째 단어를 의미한다.
(2) 문장 x와 대치되는 x' 문장도 주어진다. 문장 x' 또한 [x'1, x'2,,,, x'n]으로 x와 같은 형태를 갖춘다.
(3) 분류기 F를 만족하는 경우
(3-1) F(x) = o(x)일때는 = o(x') 이다. 그러나 F(x') =/= o(x')이고 여기서 o(·)는 오라클을 의미한다. 인간 의사 결정자를 의미 하는듯 하다. (본문에서는 'where o(·) is the oracle (e.g., human decision-maker)'로 표현)
(3-2) ||ti − t 0 i ||2 ≤ ϵ for i = 1, 2, ..., n 여기서 ϵ ≥ 0와 ti는 xi의 단어 임베딩을 말한다.
3. InfoBert
저자가 제안하는 두가지 Regularizer
- Information Bottleneck Regularizer
- Anchored Feature Regularizer
3.1 Information Bottleneck as a Regularizer
저자들은 가장 알맞는 표현 T를 찾는 방법을 라그랑지안 공식의 최대화 방안을 이용해 도식화 했다.
*X: input sentence
*T: word embedding sequence
*Y: output color
*q(y|t): bert
MI의 계산에서 I(intractable)
q는 변분근사(variational approximation)이다.
우변의 최대화는 작업 loss H(y|t) 최소화와 같다.
IB의 하한을 계산하기 위해 제 2항(I(X;T)의 상한을 이용한다.
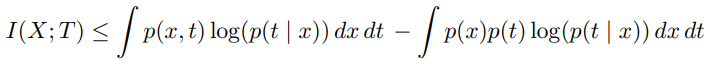
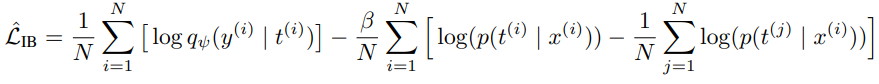
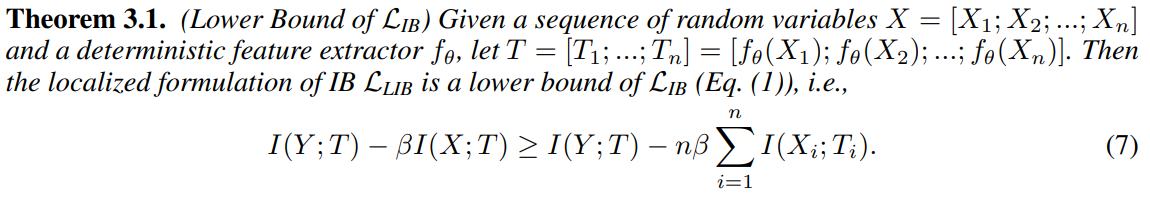
: 문장의 길이가 늘어나는 경우 = I(Y ; T)의 계산량이 너무 많아짐으로 IB의 하한선(LIB)이 극대화 된다.
* I(Y; T): 작업 loss
* 마지막 식: X의 noise로 인해 T 복잡성(complexity)이 줄어든다.
그렇다면 IB 최대화가 적대적 공격에 대한 (adversarial robustness)을 키우는 이유가 뭘까?
benign sentence x가 adversarial sentense x'가 되었을 때의 성능 차이는 다음과 같다.

IB의 최대화는 B1[ ] + B2[ ] 부분에서 효과를 발휘한다.
B3[ ]의 부분은 Adversarial training이 IB를 최대화 하는 방식과 조합될 때 Adversarial robustness가 한층 더 향상함을 알 수 있다.
3.2 Anchored Feature Regularizer
IB Regularizer는 적대적 공격을 유발할 수 있는 노이즈가 많은 정보를 억제하는 Regularizer이다.
저자들은 이 외에도 로컬에서 안정적으로 특징을 추출하고 문장 전역에 걸쳐서 표현을 정렬해 언어 표현의 안정성과 견고성을 향상시키는 새로운 정규화기 Anchored Feature Regularizer를 제안했다.
로컬 고정 기능 추출(local anchored feature extraction)의 목표는 후속 작업에 유용하고 안정적인 정보를 전달하는 feature를 찾는 것이다.
저자들은 nonrobustness하고 unuseful한 기능을 검색하는 것 부터 시작한다.
이 Regularizer는 로컬에서 강력하지 않은 feature를 구별하기 위해 적대적 단어로 대체 될 시에 어떤 단어가 변경되기 쉬운지 탐지하고자 적대적 공격을 수행한다. 저자들은 이러한 취약 단어를 적대적 위협에 대응하기 어려운 특징으로 간주했다.

알고리즘은 local feature 즉, 단어를 받아 들이고 local anchored feature의 인덱스를 반환한다.
사용 예제는 다음과 같다.
- 본인의 작업에서 유용하고 강력한 기능(의미를 지닌)을 추출하고 싶을 때 사용한다.
- 위 과정을 위해서 문장 전체에서 nonrobustness하거나 unuseful한 local feature를 찾아 제거하는 것을 목표로 한다.
- 1. nonrobustness: 단어 수준에서 성공적인 공격과 같은 것으로 한다. (ex. 그러한가?, 부정문과 긍정문 등)
- 2. unuseful: 변경 사항이 문장 전체의 정확도에 영향을 미치지 않는다. (ex. 말미, 어미 등)
- 단어 수준에서 perturbation이 적용될 때 성능 변화에 미치는 영향은 nonrobustness에서는 너무 크고, unuseful의 경우는 너무 작은 것을 제외하면 작업의 전 과정에 있어서 적당히 robustness하고 useful한 feature만 남는다.
useful하면서도 robustness한 단어 Ti와 글로벌 feature z([CLS] embedding)의 상호 정보 길이를 최대화한다.
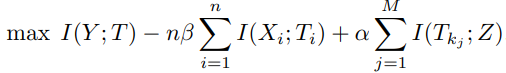
대신 마지막 MI항은 InfoNCE(van den Oord et al., 2018)를 하한을 최대화한다.
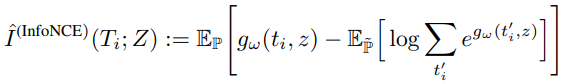
Expreimental setting
[Data set]
- Adversarial NLI (ANLI) (Nie et al., 2020)
- Adversarial SQuAD (Jia and Liang, 2017)
- Text Fooler (Jin et al., 2020)
[Model]
- Apply InfoBERT to BERT-large and RoBERTa-large
[Baseline]
- FreeLB (Zhu et al., 2020)
- SMART (jiang et al., 2020)
- ALUM (Liu et al., 2020)
Result
실험결과는 다음과 같다.
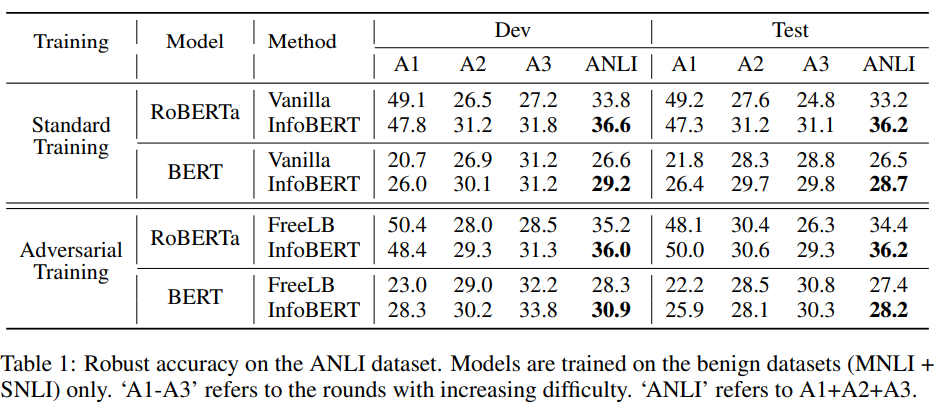
- 바닐라 RoBERTa와 BERT는 예제에 대해 강력한 adversarial training이 불가능했다.
- InfoBERT는 standard training과 adversarial training 모두에서 robustness가 향상되었다.
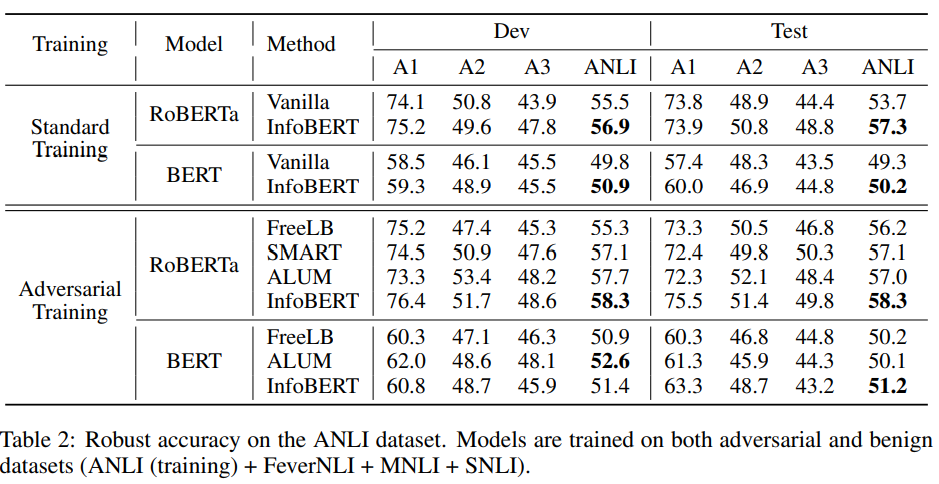
- 훈련 데이터를 변경해서 실험해 보았을 때.
- ANLI를 이용한 실험에서 sota를 달성.
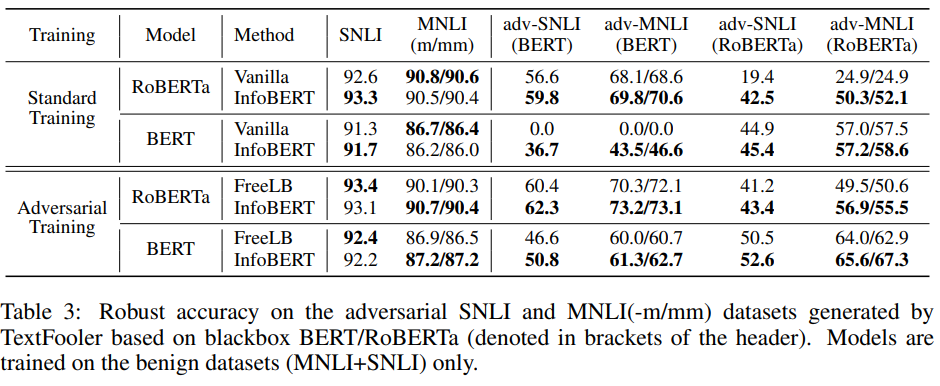
*TextFooler에 의해 생성된 adversarial examples에서의 Robustness
- Benign Dataset에 미치는 영향도 거의 없음
- Theorem 3.2에서 이론적으로 증명한 InfoBERT + Adversarial training 조합을 실험적으로 입증했음.
- BERT-large의 accuracy가 대폭 향상되었음을 볼 수 있음.
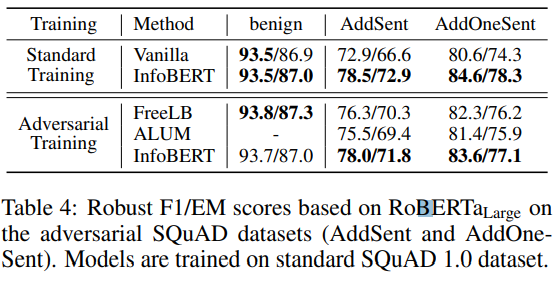
- QA에서도 실험을 진행해 보았다.
- InfoBERT가 대체적으로 좋은 성능을 보여준다.
- standard training + InfoBERT는 Adversarial training + FreeLB 보다 좋은 성능을 보여줌
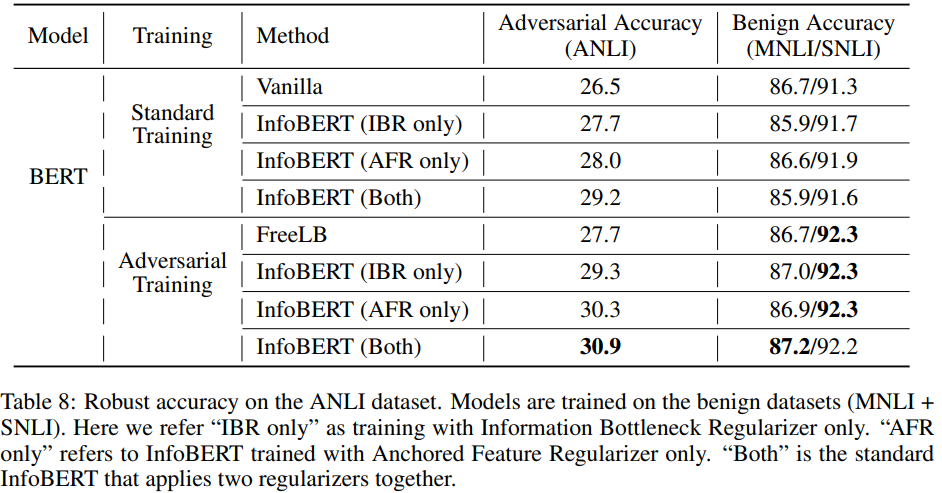
- IBR(Information Bottleneck Regularizer)과 AFR(Anchored Feature Regularizer)을 성공적으로 검증함.
Summary
- 저자들은 이론적인 부분도 잃지 않으면서 두개의 Regularizer를 추가하는 방식의 InfoBERT라는 학습 방법을 제안했다.
- 이 방법은 순정 데이터 세트의 정확도를 크게 잃지 않고 NLI와 QA등 여러 데이터 세트에서 적대적 Robustness를 향상시켰다
- Adversarial attack과 InfoBERT의 조합은 이론적으로도 실험적으로 효과적인 방법이었다.